前言
之前就准备了一堆python的书籍,比如python爬虫教程、python科学计算、python的数据处理等等。 前几天看了一点,但没细看,今天打算先看一下pandas库的创作者写的:利用python进行数据处理
记录1
没找到这本书用的原始数据,就没办法每一步都跟着作者重复一遍,所以就针对某一些觉得有用的小技巧记录一下~
首先作者讲到了本书主要利用的是IPython和一些安装方法,wins上面无非就是
pip3 install ipython
pip3 install jupyter
pip3 install pandas
最后在命令行可以检测是否安装成功,我用的是Git Bash,因为cmd真的不忍直视…
David@Wins ~
$ python
Python 3.8.2 (tags/v3.8.2:7b3ab59, Feb 25 2020, 23:03:10) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
David@Wins ~
$ ipython --pylab
Python 3.8.2 (tags/v3.8.2:7b3ab59, Feb 25 2020, 23:03:10) [MSC v.1916 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 7.14.0 -- An enhanced Interactive Python. Type '?' for help.
Using matplotlib backend: TkAgg
In [1]: import pandas
In [2]: plot(arange(10))
Out[2]: [<matplotlib.lines.Line2D at 0x241142e2be0>]
也可以检测一下notebook是否成功安装:
David@Wins ~
$ ipython notebook
测试结果如图:
文中常用的库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
接下来,我了解到了json库的一个用法:
import json
records = [json.loads(line) for line in open(path)]
loads 命令可以把json文件的内容变成字典形式,且针对于字典的键对应的值进行统计并排序:
-
统计:
def get_counts(sequence): counts = {} for x in sequence: if x in counts: counts[x] += 1 else: counts[x] = 1 return counts -
排序:
def top_sequence(counts,n=10): value_key_Pairs = [(count,key) for key,count in counts.items()] value_key_Pairs.sort() #降序 return value——key_Pairs[-n:]或
from collections import Counter counts = Counter(key) counts.most_common(10) #降序输出前10个还可以利用pandas
from pandas import DataFrame, Series import pandas as pd; import numpy as np frame = DataFrame(records) frame['key'][:10] #输出前10对应的键和序号 counts = frame['key'].value_counts() counts[:10] #输出前10对应的键和值 counts[:10]. plot(kind='barh',rot=0) #绘制水平柱状图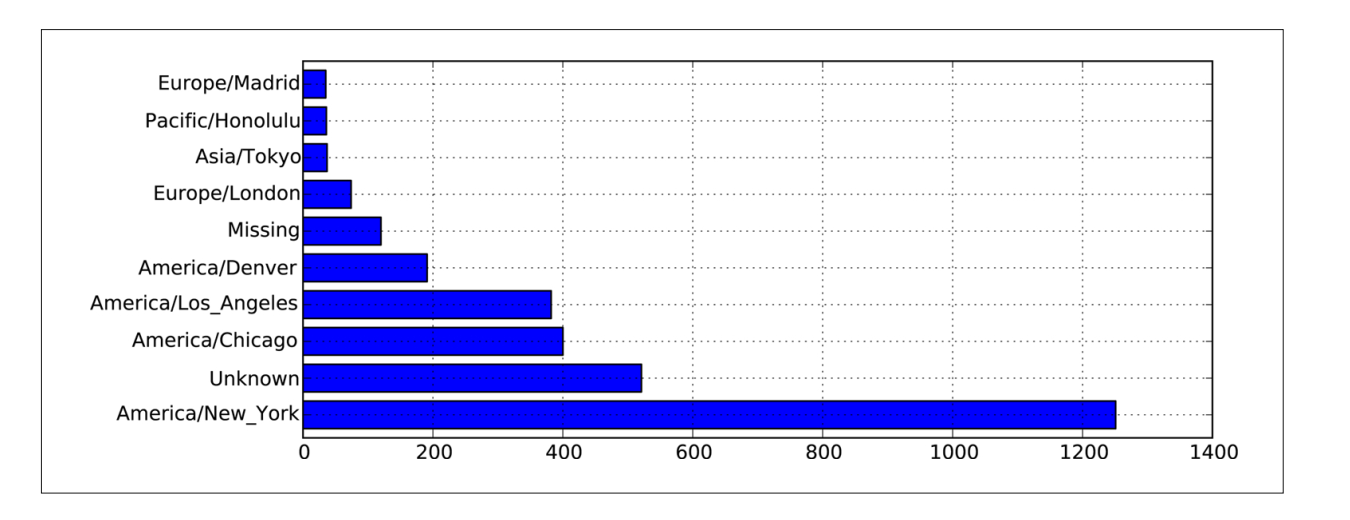
P27